Private mesh
A Tailscale/Headscale overlay joins every machine — home, mobile, and a remote VPS — into one flat, encrypted network. Nothing is exposed to the public internet that doesn’t need to be.
Strange Artificial Machine — a self-hosted AI and infrastructure fleet of twenty machines that runs like one. It powers every tinyblue public site, every client deployment, and a roster of persistent agents — with zero cloud dependencies and no recurring inference bill.

This case page checks its own route brief, public freshness score, and visitor-route signal before asking anyone to trust the story.
Loading the citation-safe case brief.
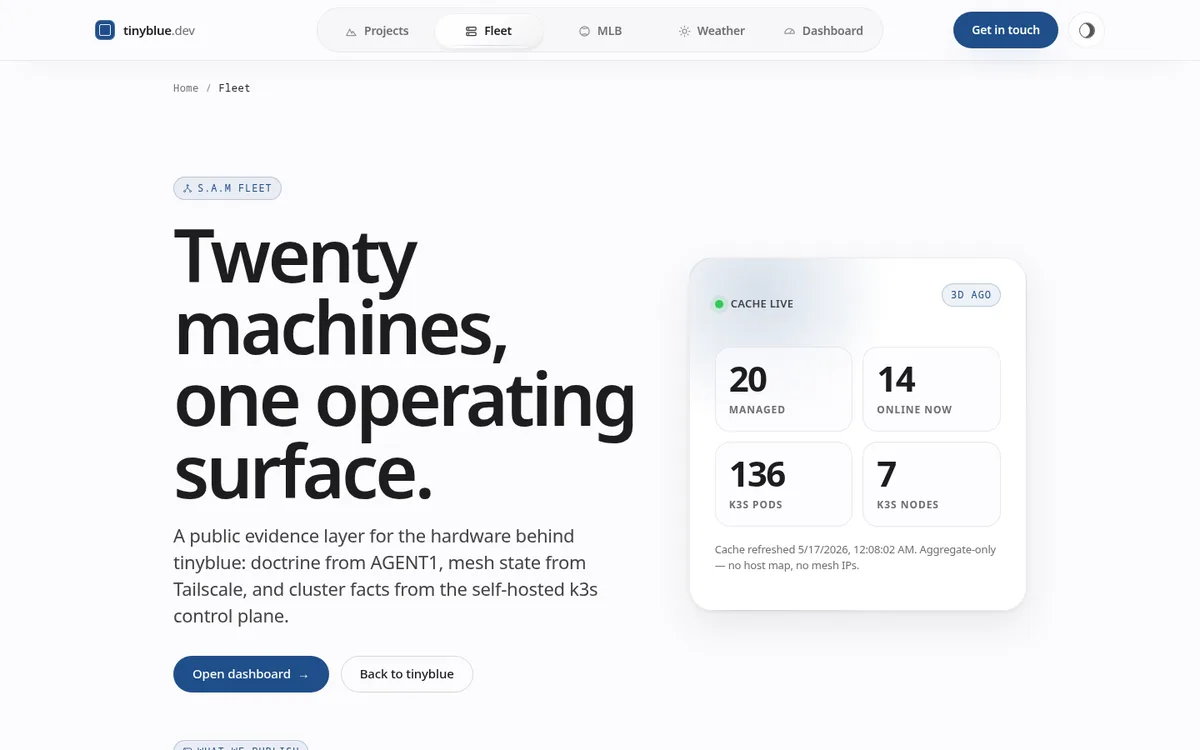
Snapshot pendingS.A.M is the substrate everything else on this site runs on. It’s a heterogeneous fleet — servers, workstations, laptops, and GPU boxes — stitched into a single private mesh, running a shared k3s cluster and a common doctrine that keeps every machine in agreement when no one’s looking.
The goal was never “a homelab.” It was a production control plane I fully own: somewhere to host client sites, run always-on AI agents with real memory, and ship product end-to-end without renting compute or handing data to a third party.
This isn’t a screenshot. These numbers come straight off the mesh through a same-origin, aggregate-only endpoint — refreshed live while you read.
Running real products on hosted AI means three compounding problems: cost that scales with success (every token is metered), data you don’t control (customer context lives on someone else’s servers), and agents with amnesia (no durable memory between sessions without bolting on more vendors).
I wanted the opposite: fixed-cost inference on hardware I own, customer and operational data that never leaves the mesh, and agents that remember everything across machines and restarts. That meant building the infrastructure first — not as a side quest, but as the foundation the whole tinyblue network sits on.
S.A.M is four layers that compose into one operating surface:
A Tailscale/Headscale overlay joins every machine — home, mobile, and a remote VPS — into one flat, encrypted network. Nothing is exposed to the public internet that doesn’t need to be.
A lightweight Kubernetes cluster runs the public sites and internal services as pods, scheduled across nodes so a single box going down doesn’t take a product offline.
Ollama and an EXO cluster serve open-weight models from owned GPUs — the same models that power chat, coaching, and agent reasoning across every property, at a fixed hardware cost.
A git-synced knowledge base clones to every machine, so any agent on any box wakes up with the same memory, conventions, and operating history. The fleet stays coherent without a human babysitting it.
Heterogeneous hardware drifts. The fix was a bootstrap that self-heals on every session start — each machine pulls the latest doctrine and config from a single source of truth, so the fleet converges instead of diverging.
Persistent memory across restarts and machines meant a vector store layered over the doctrine — 311K+ vectors across 29 namespaces — so an agent can recall context from work done weeks ago on a different box.
The public sites needed live fleet stats without leaking the topology behind them. I gated the status APIs to same-origin and stripped every response down to safe aggregates — counts, not machine names, IPs, or roles.
Live counts are published on the fleet page, refreshed from the cluster itself — not a screenshot.
Lightweight Kubernetes that runs on modest hardware; a private mesh so every node is reachable without opening ports.
Local model serving across owned GPUs — fixed cost, full data control, no per-token metering.
Rust for the hot paths, PHP for the web surfaces, Python for glue and agents — all sharing one knowledge base.
S.A.M is a living system, not a finished one. The active threads: tighter agent autonomy so the fleet does more unattended work, richer public observability that exposes health without ever leaking topology, and migrating more of the tinyblue product surface onto local inference so even more of the network runs at fixed cost on owned hardware.
The fleet page reads live from the cluster — or browse the rest of the work.